La gestion avancée des flux IP : Les flux multimédias : Codec audio G.7xx - codec vidéo H.26x - MPEG
CHAPITRE XIII : La gestion avancée des flux IP : Les flux multimédias
Les flux multimédias : Codec audio G.7xx - codec vidéo H.26x - MPEG
L’objectif de ce chapitre est de présenter les caractéristiques des flux multimédias (essentiellement la voix et la vidéo), afin de montrer comment leurs particularités influent sur un réseau de paquets tel que TCP/IP.
L’objectif de ce chapitre est de présenter les caractéristiques des flux multimédias (essentiellement la voix et la vidéo), afin de montrer comment leurs particularités influent sur un réseau de paquets tel que TCP/IP.
Il n’a pas pour objet de faire de vous des experts en audiovisuel, mais plutôt de vous donner les informations essentielles vous permettant de savoir de quoi on parle, ce que l’on manipule et de comprendre l’impact de ces flux audio et vidéo sur votre réseau.
Vous découvrirez ainsi :
- comment sont transportés le son et l’image sous forme numérique ;
- ce qu’est un codec audio et vidéo ;
- les problèmes posés par les délais de transit et la gigue ;
- quels débits ces types de flux engendrent sur votre réseau.
Les caractéristiques des flux multimédias
Initialement, un réseau IP, tel que l’Internet, était conçu pour véhiculer des données entre deux machines : transfert de fichiers, connexion Web, messagerie, etc. Depuis, la voix et l’image ont fait leur apparition et ont étendu le champ d’utilisations du réseau : téléphonie, diffusion de films à la demande et conférences à plusieurs. Dans ce dernier domaine, on distingue l’audioconférence (voix uniquement), la visioconférence (voix + vidéo) et, d’une manière générale, la téléconférence (voix + vidéo + données).
Ces flux multimédias induisent un certain nombre de contraintes nouvelles :
- Les signaux audio et vidéo doivent être numérisés, ce qui veut dire convertir les signaux analogiques en bits numériques.
- La voix nécessite une bonne synchronisation entre l’émetteur et le récepteur.
- La vidéo engendre une augmentation du volume des données transférées.
- La téléconférence nécessite de diffuser un flux entre un émetteur et plusieurs récepteurs qui peuvent devenir, à leur tour, émetteurs.
La numérisation des signaux nécessite d’échantillonner la voix, de la quantifier, de la coder et, de plus en plus souvent, de la compresser :
- L’échantillonnage consiste à prélever des échantillons du signal à intervalles réguliers, à l’instar du cinéma qui utilise 24 images par seconde pour traduire le mouvement. Ainsi, plus la fréquence d’échantillonnage sera élevée, plus le nombre de bits utilisés pour représenter un échantillon sera grand et plus la forme numérique sera fidèle au signal original. En contrepartie, le débit réseau généré sera plus important. La plupart du temps, l’échantillon porte sur 8 bits, alors que, pour la haute fidélité (requise, par exemple, pour un Compact Disc), l’échantillon porte sur 16 bits.
- La quantification fait correspondre une valeur à l’amplitude d’un échantillon par rapport à des valeurs-étalons appelées niveaux de quantification. L’amplitude des échantillons prélevés peut varier de façon illimitée, mais doit pouvoir être représentée par un nombre fini de valeurs binaires. La valeur résultant, généralement codée sur un octet, sera égale au niveau de quantification le plus proche de celui mesuré.
- Le codage consiste à transmettre un flux d’informations binaires correspondant à l’échantillon représenté par un octet.
- De plus en plus souvent, le codage est associé à un algorithme de compression.
Par exemple, la voix génère des signaux à une fréquence oscillant entre 300 Hz et 3 300 Hz, valeur arrondie à 4 000 Hz par les équipements numériques. Un chercheur, appelé Shannon, a montré que la fréquence d’échantillonnage devait être égale au double de la fréquence du signal à numériser. Un signal analogique de 4 000 Hz nécessite donc 8 000 échantillons par seconde, qui sont représentés sur 8 bits, soit un débit de 64 Kbit/s pour coder la voix. Cette unité, appelée DS0 (Digital Signaling 0), a longtemps été la référence et continue encore de l’être pour les liaisons d’accès E1/T1 proposées par les opérateurs, aussi bien pour la voix que pour les données.
--------------------------------------------------------------------------------------------------------
LES CODEC AUDIO
Il existe une multitude de codec, que l’on peut ranger en trois catégories : temporel, source et hybride. Cette différenciation repose sur la manière dont est réalisée la quantification.
La quantification différentielle consiste à mesurer la différence entre deux échantillons. L’échelle utilisée peut être fixe, on parle alors de quantification différentielle scalaire (de type linéaire ou logarithmique), ou varier en fonction du signal précédent, qui est appelée quantification différentielle adaptative.
Au lieu de travailler échantillon par échantillon, la quantification vectorielle travaille sur un groupe d’éléments qui sont codés à l’aide d’un dictionnaire (codebook). Ce type de quantification peut être appliqué à des échantillons de voix ou à des paramètres quelconques.
Les codeurs temporels (waveform)
Les codeurs de ce type codent directement le signal d’entrée, échantillon par échantillon. Cela est le cas des codec de type PCM (Pulse Code Modulation) qui utilisent une quantification différentielle logarithmique (loi A ou loi µ) et des codec de type ADPCM (Adaptative Differential PCM) qui reposent sur une quantification différentielle adaptative.
Les codeurs sources
Cette catégorie est constituée par des algorithmes qui transmettent les paramètres de la voix (intensité et fréquence principalement) au lieu d’une représentation du signal lui même. La voix est modélisée par une fonction d’excitation choisie parmi plusieurs. À la réception, la voix est reconstituée en utilisant cette fonction et les paramètres qui ont été transmis.
Les plus répandus de cette famille sont les algorithmes à prédiction linéaire (LPC – Linear Prediction Coding). Ils utilisent une combinaison des échantillons précédents pour construire une valeur prévisible approchant le plus possible l’échantillon à coder. Ils sont spécifique au codage de la voix (tout autre son serait restitué avec une très mauvaise qualité). C’est pour cela que les codec utilisant ce type d’algorithme sont appelés vocoder (voice coder). Ils produisent une voix d’aspect synthétique, mais le débit réseau généré est très bas. Par exemple, LPC10 (10 coefficients) code des trames de 20 ms sur 54 bits, ce qui donne un débit de 2,4 Kbit/s.
Un autre type d’algorithme fréquemment utilisé est le LTP (Long Term Predictor), qui s’attache à construire une valeur prévisible de la fréquence du son.
Les codeurs hybrides
Ces codeurs combinent l’utilisation des technologies temporelles et source, en plus de l’utilisations de méthodes de quantification vectorielles.
La méthode la plus utilisée est l’analyse par synthèse (ABS – Analysis By Synthesis), technique sur laquelle se basent les codec de type MPE (MultiPulse Excited), MP-MLQ (MultiPulse Maximum Likelihood Quantization), RPE (Regular-Pulse Excited), et surtout CELP (Code-Excited Linear Predictive). Elle consiste à analyser le signal d’entrée en synthétisant différentes approximations déduites des signaux précédents.
Citons également les variantes LD-CELP (Low-Delay CELP) et CS-ACELP (Conjugate-Structure Algebraic CELP).
Un codec ABS travaille sur des groupes d’échantillons appelés trames, typiquement longues de 10, 20 ou 30 ms. Pour chaque trame, le codec détermine les coefficients d’un codage source (appelé ici filtre), puis choisit une fonction d’excitation qui sera appliquée à ce filtre. Les codes transmis correspondent aux paramètres tels que ceux nécessaires à LPC, RPE et LTP.
Quelques techniques complémentaires peuvent être utilisées par les codec.
Le codage en sous bande
Nombre de codeurs récents utilisent, en plus, une technique de codage en sous bande (SBC - Sub-Band Coding) également appelée codage psychoacoustique. Cette technique consiste à découper le signal d’entrée en sous-fréquences et à utiliser plus de bits pour coder les fréquences les plus audibles. En d’autres termes, l’algorithme concentre les efforts de codage sur les fréquences auxquelles notre oreille est la plus sensible.
Le premier algorithme à employer cette technique a été G.222, un codec de type temporel. Il utilise deux sous-bandes sur lesquelles sont appliquées un codage ADPCM, tandis des codec hybrides plus récents tels
que MPEG utilisent jusqu’à 32 sous-bandes.
Le codage des silences
Par ailleurs, les codec intègrent des détecteurs de silence (VAD – Voice Activity Detection). Lors d’une conversation, les silences représentent, en effet, 35 à 40% du temps global.
--------------------------------------------------------------------------------------------------------
Les quatre opérations constituant la numérisation d’un signal analogique (audio ou vidéo) sont réalisées par des processeurs spécialisés appelés DSP (Digital Signaling Processing).
Les algorithmes qui définissent la manière de réaliser ces opérations sont appelés Codec (codeur/décodeur).
Les codec étant normalisés ITU-T, série G, leurs noms commencent par cette lettre. Le premier d’entre eux et le plus utilisé sur les liaisons E1/T1 ainsi que sur le RTC, répond à la norme G.711. Le codage est de type PCM (Pulse Code Modulation) ; il n’utilise aucun algorithme de compression. En France, la norme est appelée MIC (modulation par impulsions codées), d’où le nom des liaisons à 2 Mbit/s proposées par France Télécom (32 canaux DS0, dont 2 pour la signalisation).
Le codec G.711 existe en deux variantes de codage : A-law (Europe) et µ-law (Amérique du Nord et Japon).

Choisir un codec audio
Pour notre oreille, la qualité d’un codec se résume à sa qualité acoustique. Celle-ci dépend de la fréquence d’échantillonnage, de la bande passante transmise (faculté à reproduire les aigus et les graves) et de la manière dont est codé le signal. L’ensemble de ses paramètres techniques se concrétise par l’appréciation subjective de l’oreille. Celle ci est évaluée par sondage sur une population d’utilisateurs et s’exprime par un indice de satisfaction moyen, le MOS (Mean Opinion Score).
Pour la voix sur IP, la qualité d’un codec dépend d’autres facteurs :
- du délai des opérations de codage et de décodage ;
- du débit réseau généré ;
- de la sensibilité aux erreurs. Par exemple, le codec G.726 est moins sensible que G.711, tandis que G.723 tolère un taux d’erreur de près de 3%. Généralement, la perte d’un paquet IP a un impact très important sur les codec PCM et ADPCM (la resynchronisation de l’émetteur sur les échantillons est difficile) et moins sur les codec hybrides ;
- de sa complexité, donc de la puissance processeur requise pour le codage et le décodage. Pour certains codec, l’utilisation de DSP s’avère souvent préférable.
Caractéristiques
D’autres paramètres, très techniques, caractérisent cependant les codec.
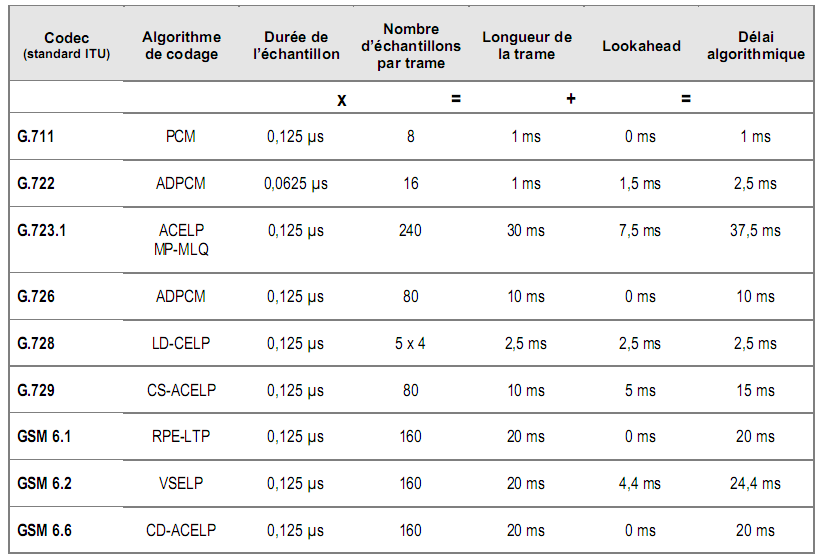
Le lookahead (analyse en avant) représente le temps moyen d’analyse d’une partie de l’échantillon N+1 permettant de prédire l’évolution du signal et de coder l’échantillon N.
Le délai algorithmique, ou délai de traitement, d’un codec correspond donc à la taille de la trame augmentée du lookahead.
Cependant, les codec temporels ne travaillent pas sur des trames mais uniquement échantillon par échantillon. Transportés dans des paquets IP, ces échantillons de 125 microsecondes sont regroupés pour former l’équivalent d’une trame.
Au délai de traitement du codec, il faut donc ajouter le temps mis pour remplir une trame.
Par exemple, le codec G.723 génère une trame contenant 30 ms de voix. Elle comporte 240 échantillons compressés à 189 bits (24 octets) ou à 158 bits (20 octets), les deux premiers bits indiquant respectivement le type de codec et la taille de la trame.
Performances
Quelle que soit sa complexité, un codec doit coder et décoder les échantillons selon un temps fixe déterminé par la fréquence d’échantillonnage. Selon la complexité de l’algorithme, un codec requerra donc plus ou moins de puissance, évaluée en Mips (millions d’instructions par secondes). En outre, la puissance requise par un codec est plus importante si le calcul est effectué en virgule flottante que s’il est effectué en virgule fixe.
Les processeurs spécialisés que sont les DSP exécutent en une seule instruction et en un seul cycle horloge des calculs répétitifs comme, par exemple, « (a*b)+résultat précédent », calculs que des processeurs généralistes comme le Pentium exécutent en plusieurs instructions et plusieurs dizaines de cycles. Les DSP intègrent également les dictionnaires (codebook) utilisés par les codec Hybrides.
Les valeurs présentées ci-après sont les moyennes indiquées par un constructeur pour ses DSP en virgule fixe. Elles ont été arrondies aux valeurs les plus proches. Pour les codec temporels, la puissance de calcul est quasi identique en codage et en décodage, alors que pour les codec hybrides, une puissance plus importante est nécessaire au codage.


(1) Les codec G.722 et G.723 sont des codec combinés (embedded) : ils changent automatiquement de débit.
(2) G.727 est la version combinée de G.726.
À titre de comparaison, un processeur Pentium cadencé à 100 MHz fournit une puissance d’environ 166 Mips (source Intel).
Qualité
En dehors des performances intrinsèques d’un codec résultant des paramètres qui viennent d’être décrits, sa qualité dépend essentiellement de l’échantillonnage et du taux de compression : plus ce dernier est élevé, plus la voix apparaît métallique à celui qui l’écoute.
Sans compression, le codec G.711 sert de référence pour la qualité de la voix sur le téléphone, référence qui est appelée toll quality. La perception de la qualité de la voix est subjective. C’est pour cela qu’elle est mesurée à travers un indice moyen de satisfaction appelé MOS (Mean Opinion Score), sur une échelle allant de 0 (très mauvais) à 5 (très bon).

Les voix ayant une sonorité métallique obtiennent un MOS inférieur à 3 ; celles acceptables pour une communication téléphonique, un MOS compris entre 3 et 4. Au-delà de 4, la qualité est excellente.
Le choix d’un codec résulte donc d’un compromis qualité/débit sur le réseau utilisé. Ainsi, le programme Netmeeting permet-il de sélectionner le plus approprié à votre contexte (menu « Outil→Options→Audio→Avancé »).

Les codec vidéo
Une image vidéo affichée sur un écran de PC représente 640 × 480 points en 16,7 millions de couleurs (24 bits) × 25 images par seconde, ce qui correspond à un débit de 23 Mbit/s (640 × 480 × 3 × 25).
Afin de diminuer le débit généré sur le réseau, une première solution consiste à diminuer le nombre d’images par seconde. La meilleure solution consiste cependant à compresser les images, à l’instar de la voix.
Pour les données, aucun bit ne doit être altéré dans les phases de compression et de décompression : la décompression d’un fichier doit reproduire exactement le fichier original. Les taux de compression sont, en moyenne, de 1 pour 2, voire plus pour les images bitmap.
Mais, pour la vidéo, l’image décompressée peut être différente de la même image avant compression. Ainsi, une légère variation de couleur ou la suppression d’un pixel n’est pas perceptible lorsqu’ils affectent 1 image sur 25 par seconde. Ce principe permet d’atteindre des ratios de compression de 1 pour 100, voire 1 pour 300. Une perte de qualité est acceptable à partir du moment où elle est à peine perceptible.

Principes de compression des images
La compression peut être spatiale (c’est-à-dire porter sur une image — mode intraframe) ou temporelle (c’est-à-dire porter sur plusieurs images dans le temps — mode interframe).
Dans le mode intraframe, l’image est divisée en blocs de 8×8 pixels : les pixels et leurs couleurs associées sont convertis en fréquence de changement de couleurs et amplitude des variations de couleurs. La moyenne est calculée sur le résultat, de manière à ce que la perte d’informations qui en résulte ne soit pas perceptible par l’œil. Les données sont ensuite compressées par différents algorithmes.
Dans le mode interframe, seule la différence entre deux images est transportée à partir d’une image de référence (key frame) ou à partir de l’image précédente. Une technique de compensation de mouvement est, de plus, utilisée : le delta est calculé non pas, pixel par pixel, mais par bloc de pixels en mouvement.
Parce qu’image après image, le mode interframe dégrade l’image de manière trop importante, il est nécessaire de transmette régulièrement l’image complète en mode intraframe.
Par exemple, M-JPEG (Motion JPEG) utilise un algorithme spatial (série d’images JPEG), alors que les normes MPEG et H.26x utilisent une combinaison des deux.
--------------------------------------------------------------------------------------------------------
LE POINT SUR MPEG (ISO CD 11172-2)
La norme MPEG (Moving Pictures Expert Group) est structurée en trois couches : la première, dite système, a trait à la synchronisation et au multiplexage des flux, la seconde à la compression de la vidéo et la troisième à la compression de l’audio. La norme utilise également le terme « couche » pour désigner les unités de travail sur lesquelles s’appliquent les fonctions de compression d’image et également pour désigner les trois niveaux de qualité audio (I, II et III). MP3 tire son nom de la qualité de niveau III.

Il existe 3 versions de MPEG : MPEG-1, MPEG-2 et MPEG-4. La version 3 n’a jamais vu le jour, car une simple évolution de MPEG-2 s’est avérée suffisante pour atteindre les objectifs assignés à MPEG-3.
La norme MPEG-1 produit des images de toutes tailles et à tous les débits, jusqu’à 80 Mbit/s, définies par des paramètres appelés CPB (Constrained Parameters Bitstream). Les formats les plus couramment utilisés sont le SIF (Standard Interchange format) et le CCIR-601 (Comité Consultatif International Radio). Les débits générés dépendent de la résolution et du nombre d’images par seconde.

En plus des trames I (Intra frame) et P (Predicted frame), l’algorithme MPEG produit des trames B (Bidirectional) résultant du codage opéré sur l’interpolation des trames précédentes et futures. La séquence de trames produites ressemble ainsi à la suivante : IBBPBBPBBPBBIBBPBBPBBPBBI... (une trame I toutes les douze trames).
La compression résulte d’une série d’opérations appliquée à l’image complète (trames I) ou à des portions d’image (trames P), celles qui ont changé par rapport à l’image précédente. Dans les deux cas, l’image ou la portion d’image est codée avec l’algorithme DCT, quantifiée, puis successivement codée par RLE et par entropie (selon la fréquence des valeurs).
Le codage DCT (Discrete Cosine Transform) permet de représenter l’image par des fréquences, seuls les coefficients d’une fonction sinusoïdale étant générés. La quantification a pour objectif de réduire le nombre de coefficients DCT à coder (comme pour la voix, certaines informations sont alors perdues). Le codage RLE (Run Length Encoding) remplace les valeurs successives identiques par un code de quelques octets.
Le codage par entropie consiste à trier les valeurs par fréquence d’apparition puis à les remplacer par des codes plus petits.
Concernant l’audio, les débits vont de 32 Kbit/s à 448 Kbit/s selon la qualité du son, s’il est stéréophonique, etc.

Par exemple, pour une qualité CD (Compaq Disc) avec un échantillonnage à 44,1 KHz, la couche III génère un débit de 128 Kbit/s (trames de 417 octets).
La norme MPEG-2 utilise, quant à elle, des algorithmes améliorés offrant des performances de 10 à 20 % supérieures à celles MPEG-1 tout en étant compatible avec ce dernier. Les paramètres CBP sont remplacés par une combinaison de quatre profils (algorithmes utilisés et fonctions activées) et de quatre niveaux définissant les paramètres (résolutions minimale et maximale, échantillonnage, couches audio et vidéo supportées, débit maximal, etc.).
La principale caractéristique de MPEG-4 (ISO 14496) est son orientation objet. Appliqué aux images de synthèse, l’algorithme de codage décrit les objets, leur forme, leur texture, leur dimension (2D ou 3D) en s’appuyant sur les spécifications VRML (Virtual Reality Modeling Language). Son objectif est également de produire des vidéos à bas débit, de 64 Kbit/s à 1,5 Mbit/s. Les applications visées par cette norme sont, par
exemple, DivX (Digital Video Express), les bases de données multimédias et interactives, le vidéophone, l’audiovisuel mobile, etc.
--------------------------------------------------------------------------------------------------------
La norme H.261 promue par l’ITU-T repose sur les mêmes principes que MPEG, mais consomme moins de CPU pour la compression. De plus, l’algorithme permet d’augmenter la compression, au détriment cependant de la qualité des images qui bougent vite (s’il existe plus de 15 pixels de différence entre deux images, l’image devient floue).
La norme H.263 est une amélioration de H.261 : elle permet de consommer 50% de bande passante en moins et de récupérer plus facilement les erreurs de transmission, et ce, pour une qualité équivalente.
Le CIF (Common Intermediate Format) est le format de base d’une image respectant les normes H.26x.

Généralement, le format QCIF est utilisé lorsque la bande passante est inférieure à 192 Kbit/s (p <= 3). H.261 et H.263 travaillent sur des GOB (Group Of Block) de 33 macroblocs (soit 198 blocs). Le format QCIF correspond ainsi à 1 GOB.
Les problèmes posés par les transmissions audio et vidéo
Il ressort de cette présentation que le trafic réseau généré par les codec vidéo est par nature erratique, les pointes de débit correspondant aux transmissions de trames I (50% du volume du trafic), et les débits les plus faibles correspondant aux trames P et B.

En revanche, le trafic audio est plutôt continu, et surtout beaucoup plus faible que les flux vidéo.
Les flux audio et, dans une moindre mesure, les flux vidéo sont sensibles à plusieurs phénomènes :
- l’écho ;
- le délai de transit (encore appelé latence), c’est-à-dire le temps qui s’écoule entre la prononciation d’un mot et sa restitution côté récepteur ;
- la variation du délai de transit, appelée gigue (jitter, en anglais).
Le phénomène d’écho provient de la réflexion du signal sur le câble, surtout au niveau des convertisseurs 2 fils/4 fils présents en nombre sur le RTC. Il est surtout perceptible sur de longues distances et est amplifié si les délais de transit sont importants. Si ces derniers sont assez bas (moins de 50 ms), l’écho n’est pas perceptible et est masqué par la conversation.
Étant donné que les délais de transit sont, la plupart du temps, supérieurs à 50 ms, des appareils spécifiques, appelés annulateurs d’écho (ITU G.165), sont systématiquement utilisés sur le RTC.
Le délai de transit affecte une conversation téléphonique : si le temps qui s’écoule entre la fin d’une phrase et sa réception complète par le récepteur est trop long, les personnes commencent à parler en même temps puis s’arrêtent en même temps, se coupent la parole, etc.
La norme G.114 préconise un délai de transmission maximal de 400 ms pour le RTC. Dans les faits, la dégradation de la qualité de la voix est nettement perceptible lorsque les délais dépassent 300 ms. De plus, l’écho devient perceptible, ce qui ajoute à la mauvaise qualité.
Les variations des délais de transit (gigues) sont essentiellement dues à la charge du réseau qui doit traiter différents types de flux. Le RTC fonctionne en mode commutation de circuit : un canal de 64 Kbit/s est réservé pendant toute la durée de la conversation. Il y a donc très peu de gigue, voire pas du tout. L’inconvénient est que la bande passante du réseau n’est pas optimisée : les 64 Kbit/s restent accaparés même lorsqu’ils ne sont pas utilisés, pendant les silences ou en l’absence de transmission.
En revanche, un réseau de paquets, de trames ou de cellules véhicule simultanément une multitude de flux et exploite au mieux ses ressources en les partageant entre plusieurs utilisateurs. Le délai de traitement varie donc en fonction de sa charge.
La variation du délai crée ainsi des interruptions inattendues au milieu d’une phrase ou d’un mot (un paquet voix arrive plus tard que les autres), qui peuvent rendre une conversation inintelligible. Pour compenser la gigue, on utilise des tampons mémoire. Les trames arrivant en retard par rapport à la moyenne sont restituées immédiatement, mais celles arrivant en avance par rapport à cette même moyenne restent plus longtemps dans la mémoire tampon.
L’inconvénient est donc que le délai de transit est augmenté proportionnellement à la taille du tampon. Généralement, cette taille correspond à un délai égal à environ deux fois celui du traitement du codec. Dans la pratique, les équipements la font varier dynamiquement.
Concernant le téléphone, notons également une spécificité liée aux fonctionnalités offertes par le DTMF (Dual-Tone MultiFrequency). Ce signal permet à un utilisateur de dialoguer avec un serveur audiotel, par exemple pour accéder au rappel sur occupation (touche « 5 » avec France Télécom) ou pour consulter son compte bancaire. La compression de la voix empêche la transmission de ce type de signal. Celui-ci est donc codé, puis régénéré à son arrivée (G.729).
Estimation du temps de transit
Le délai de transit sur le réseau est la somme des délais induits par tous les équipements traversés : câbles, routeurs, commutateurs, etc.
Il faut ainsi additionner :
- le délai de sérialisation déterminé par la vitesse de la ligne et la taille du paquet ;
- les délais de traitement propres au codec ;
- le délai de transit dans un nœud (routeur ou passerelle), déterminé par l’empaquetage et le dépaquetage des données, augmentés des temps de traitement dus aux protocoles réseau (interprétation des entêtes, routage, etc.).
La sérialisation est l’action d’envoyer les bits sur le câble. Plus le débit de la liaison est élevé, plus le temps de sérialisation est court. Par exemple, il faut 125 microsecondes pour envoyer un octet sur une LS à 64 Kbit/s contre 0,05 microsecondes sur une liaison à 155 Mbit/s. De même, plus les sites sont rapprochés, plus le délai de propagation est court. Par exemple, il faut compter 32 ms de délai de propagation sur une LS 64 Kbit/s entre l’Europe et les États-Unis.
À titre d’exemple, le tableau suivant dresse la liste des délais nécessaires pour envoyer une trame de 30 ms générée par le codec G.723.

(*) L’encapsulation dans un paquet IP ajoute 2 à 5 octets (avec compression des en-têtes RTP/UDP/IP, voir chapitre 16). Il faut ajouter à cela les entêtes Frame Relay (6 octets) ou ATM (5 octets) ou encore Ethernet, etc.
(**) Ce temps est égal à celui induit par les routeurs et/ou commutateurs et/ou passerelles, éventuellement augmenté de celui induit par la propagation des signaux sur les liaisons internes au réseau de l’opérateur.
Le transport des données multimédias
À la différence des données applicatives, la voix et la vidéo — ainsi que, dans une moindre mesure, la télécopie — acceptent l’altération des données. Il en résulte une dégradation de la qualité du son, de l’image ou de la page, qui peut toutefois être tolérée par les personnes qui les reçoivent. En plus du délai de transit et de sa variation, des paquets peuvent donc être perdus, mais bien sûr dans une certaine limite.

En outre, les liens réseau doivent être correctement dimensionnés, afin de supporter les débits générés par les flux multimédias. Ces derniers sont variables, car ils dépendent de la qualité voulue pour le son et l’image.

Sur le réseau téléphonique à commutation de circuit (RTC, RNIS), la voix occupe un débit fixe réservé entre l’appelant et l’appelé pendant toute la durée de la communication. Sur un réseau à commutation de paquets, tel qu’IP, aucun débit n’est réservé, et celui-ci peut varier dans le temps (par exemple, les silences ne sont pas transmis, etc.).
La voix peut ainsi être transmise sur IP — on parle alors des produits VoIP (Voice Over Internet Protocol) —, directement sur Frame Relay (VoFR) ou sur ATM (VoATM).
Dans tous les cas, le transport de la voix et de la vidéo requiert des mécanismes spécifiques, afin d’assurer la qualité de service requise (débit, délai de transit, variation du délai de transit, perte de paquets tolérée).
Un autre problème, qui cette fois n’est pas nouveau, est de dimensionner les liens réseau en fonction du nombre d’utilisateurs. On parlera ici de canaux, un canal correspondant à une session voix ou vidéo.
Une règle simple, mais peu économique, est de prévoir autant de canaux que d’utilisateurs :
le débit total est alors égal au débit d’un canal VoIP multiplié par le nombre d’utilisateurs. Une règle plus complexe, mais plus rationnelle, consiste à s’appuyer sur le nombre de communications simultanées et à utiliser des modèles statistiques permettant de prévoir le nombre de canaux nécessaires en fonction de différents paramètres, tels que le nombre d’utilisateurs, la durée moyenne des communications, le taux de débordement acceptable, etc.
Les modèles standards s’appuient sur des distributions de Poisson qui permettent de convertir la nature aléatoire des appels en probabilité, sur une unité de mesure appelée Erlang ou CCS (Centum Call Seconds).
En définitive, un travail d’ingénierie important est nécessaire pour préparer son réseau IP au multimédia.
-----------------------------------------------------------------------------------------------------
Article plus récent Article plus ancien